Event Notification
Why use event notification pattern?
Let’s have an example of an insurance company. If some customer changes his address, the insurance changes(re-quotes). For designing a system like this, we could have the customer management service tell the insurance quoting service whenever someone changes their address. This is the command way of doing things. Although, this creates a dependency from customer management service to insurance quoting service (customer mgmt needs to know insurance quoting service exists and its APIs, etc.). This kind of coupling isn’t generally preferred. We can have dependancy to some general service but its not preferred the other way around.
If we were to follow the above practice, we need to have a way for insurance quoting to know when the address is changed in the customer management. A way we can do this is by events, whenever the address changes the customer management service emits an event to an event queue and then insurance quoting service can listen for that event.
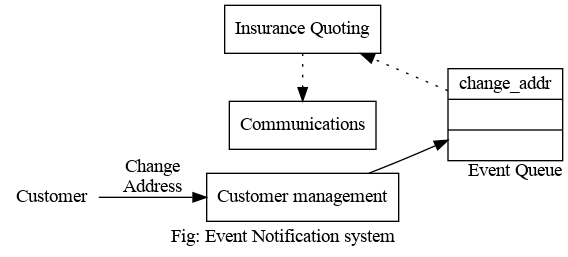
We use events as a notification mechanism between multiple systems.
Events vs commands:
If something is expected to happen for sure, we can use commands although it doesn’t give decoupling like events. The con of using events is that there is no statement for overall behaviour.
Event Carried State Transfer
Why use Event Carried State Transfer pattern?
So, now we have the customer management system publishing some event and insurance management system consumes it. Now, when it needs more information, it has to ask the customer management system. Let’s say we want to prevent this because there is more traffic coming to the customer management system from every other services.
The way we prevent this is by keeping the copy of the required data published by the customer management service. Customer management system broadcasts init events of all the data the downstream systems will ever use and the downstream systems will keep the copy of the data that they will be using.
Pros and Cons
The benefit is there is no need to call the customer management at all, which could improve the performance. It improves availability because if the customer mgmt system goes down, the insurance quoting system can still continue to work. It is a less commonly used pattern.
Pro: High Availability, Con: Low Consistency.
Event Sourcing
Why use event sourcing pattern?
Say customer wants to change his address and asks the customer mgmt system. Now we can just create a new address object for that customer and point to that. The other way of doing this is to keep an event and then process the event onto the application state. The result of this system is that we now have Application state and the logs of what events occurred.
At any point of time, we can recreate the application state by just using the logs.
Pros and Cons
The fault tolerance of such systems can be very high and they are generally very performant. We can have 2 systems running of the same events stream and if one system goes off, the other can instantly take over. There is no requirement of database to store the application state, everything can be in-memory because we can just use the logs.
Downside of event sourcing is that it can be complex in modelling the events to meet the condition that we can restore the application state just by replaying the events. Event sourcing can be done with just synchronous communication, although we can take advantage of event sourcing to add asynchronous communication in the system.
It can be difficult to capture the intent of events sometimes(say refactoring some variable, it is viewed as the textual change if not things can get a bit hairy as it depends on the specific language, the LSP implementation for different languages are different). Let’s say we have some input event and then apply some business logic and then capture the output event and the internal event which is also a result of the business logic. Now if there is some bug in the business logic, then our events which are the logs turns out to be wrong. This can be an issue. The way to solve this is to store the input event as well. The reason we capture the input event as well is to capture the intent and thereby avoiding the bugs like stated.
Fun fact: Git(Version Control) is based on event source based system. The commits are the logs.
Pros: Debugging, Historic State, Alternative State, Memory Image
Cons: Difficult to deal with external systems, event scheme can be complex, Versioning can get complicated (say application state/schema is changed, is it still possible to replay the events?)
CQRS (Command Query Responsibility Segregation)
The data models for read and write are stored separately. They are separate components (Command model and Query model). The command model is used only when we update the data store, for reads the query model is used always. This is not the same as having separate databases for read and update.
This pattern can be used when the updates are much less compared to the read operations. This pattern has to be used carefully and not everywhere.