Introduction and Overview
- This project aims to solve the problem of generating accurate animated educational videos from just the prompt (uses manim-ce under the hood with agentic pipeline using langgraph).
- The target stakeholders include educational content creators, high school and undergrad engineering students.
System Design
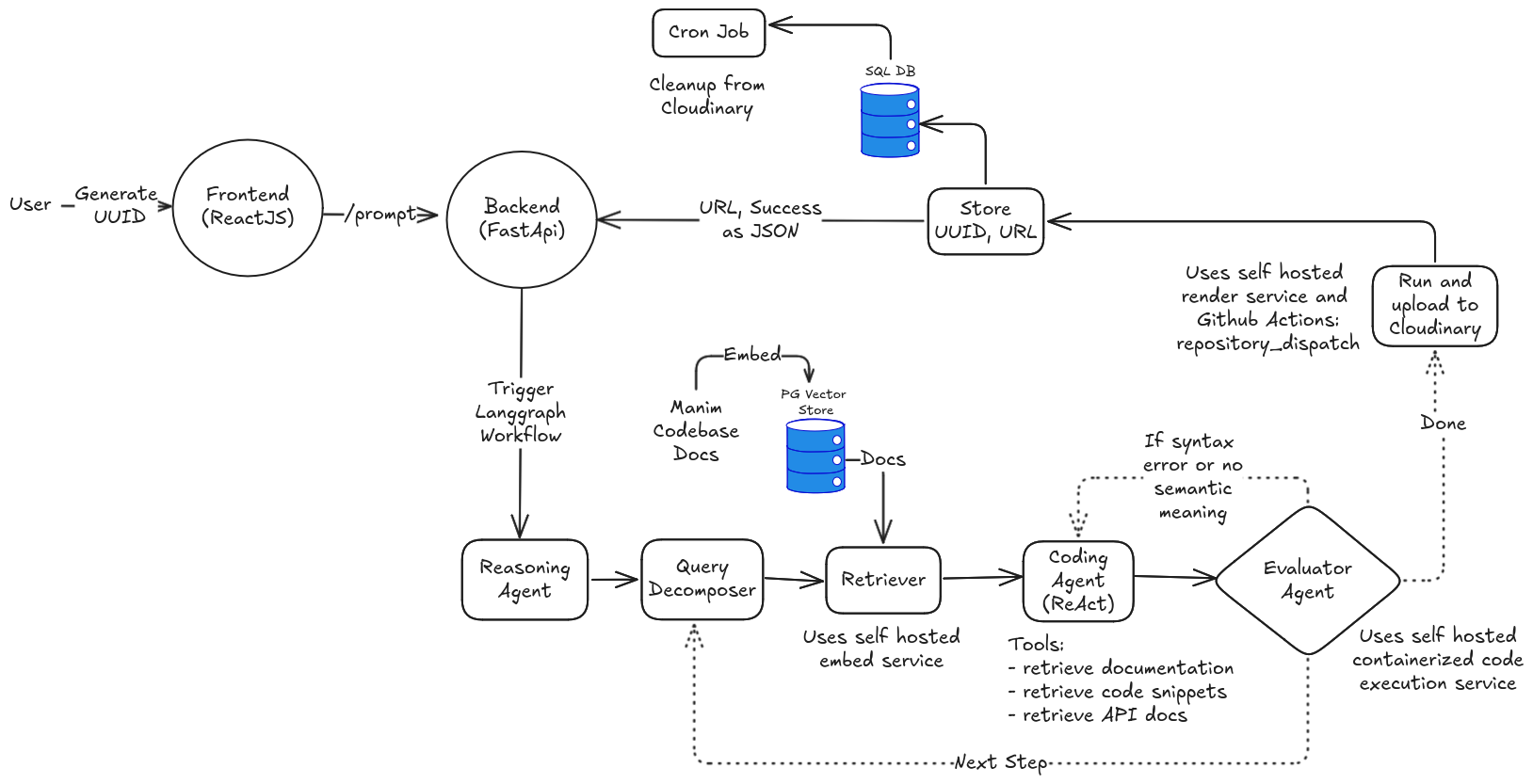
- The frontend requires no login, when an user enters the website, an unique V4 UUID gets generated and the user query is passed along with this UUID to the backend. The backend triggers the langgraph workflow.
Langgraph workflow
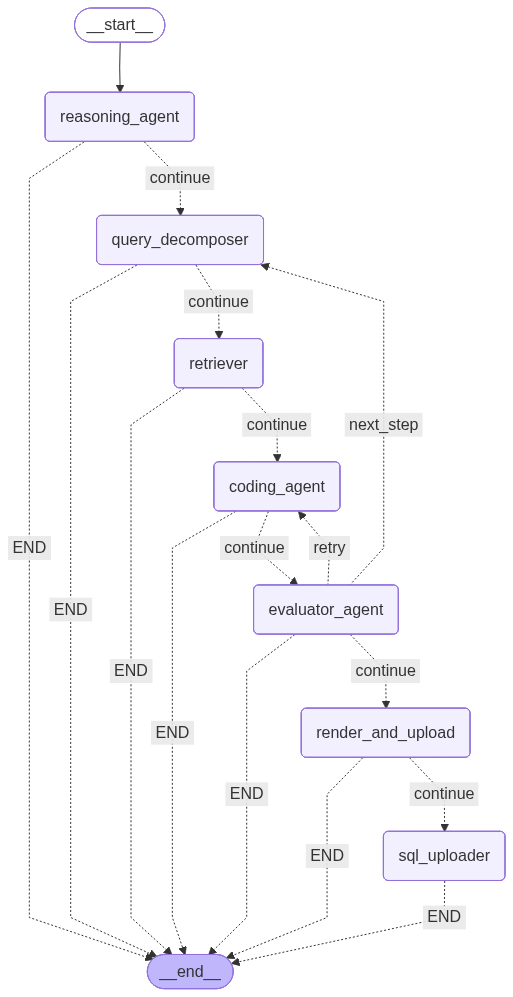
- The workflow starts with the reasoning agent which uses moonshotai/Kimi-K2-Thinking to plan out the steps required (maximum 15).
- The query decomposer chooses the current step and then creates individual prompts for querying code snippets, documentation, autosummary/references snippets (contains just functions/classes) using LLama-3.1-8b-instant model.
- The retriever retrieves a specific number of relevant documents(chunks) from the PG Vector Store for each of the categories mentioned above. For generating embeddings, I deployed Qwen3-Embedding:0.6b as a docker image in Hugging Face spaces.
- The retrieved documents, user query along with the current step for scene generation forms the context for the coding agent which also has access to tools for retrieving documents of different categories. Qwen3-32b coding model has shown some success for generating code faster, but in production moonshotai/kimi-k2-instruct-0905 is being deployed since it performs better.
- The evaluator agent runs the generated code in an isolated environment (used docker locally and then migrated to a docker image deployed in Hugging Face spaces) and then checks for syntax errors. If there is any syntax error, the control flow goes back to the coding agent with the error and the code generated as the context. If there is no syntax error, I pass the generated code to an agent (gpt-oss-safeguard-20b) which checks the generated code for semantic correctness and decides whether it has to retry or continue. If it decides to retry, the control flows back to coding agent with constructive feedback on how to improve the current code. If the model decides it can continue, the control flows to query decomposer for the next step or to the render_and_upload service based on the number of steps completed.
- The render_and_upload is a service (deployed as docker image in Hugging Face spaces) that triggers rendering and uploading part from Github actions and receives the url of rendered video via a callback url from Github actions. In Github actions, manim-ce is installed with necessary dependencies in Ubuntu base image, video is rendered from the generated code, uploaded to Cloudinary and sends the url by HTTP post request to the callback url.
- The sql_uploader uploads the uuid, query, code_generated, video_url, public_id, created_at and completed_at to a Postgres database which can be used by cron job to delete videos from Cloudinary to stay under the free tier.
- The cron job (deployed in render.com and triggered using cron-job.org) fetches the video url generated in the last 30 minutes from the Postgres database and deletes the videos from Cloudinary to stay under the free tier limits.
Data Design
- For retrieval of Manim-CE documentation, I created a Postgres table with PGVector enabled with the following schema:
| Field | Notes | Type |
|---|---|---|
| langchain_id | UUID for chunk | uuid |
| content | The content of the chunk | text |
| embedding | Vector embedding of the chunk | vector(1024) |
| langchain_metadata | Metadata relevant for each chunk | json |
- For storing the metadata of the generated video, I have created another Postgres table with the following schema:
| Field | Notes | Type |
|---|---|---|
| uuid | UUID of the user (generated by frontend) | uuid |
| query | The query given by the user | varchar(1000) |
| code_generated | The final code generated for the given query | varchar(2000) |
| url | URL of the rendered video uploaded on Cloudinary | varchar(200) |
| public_id | Public of the rendered video to be used for deletion | varchar(60) |
| created_at | Time at which the rendering process started | timestamp |
| completed_at | Time at which the rendering process completed | timestamp |
Interface Design
Laptop and desktop
Tablet

Mobile
Component Design
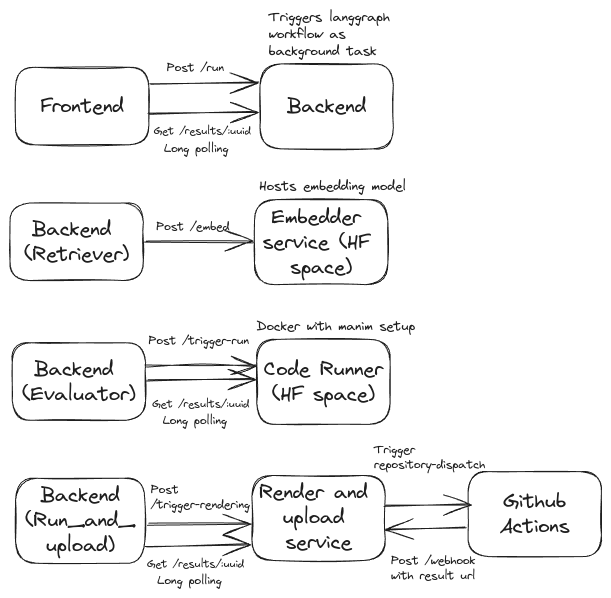
- Code runner service, render and upload, the main backend all support long polling (and SSE, but long polling is preferred for the required use case).
- Code runner uses redis for job management, although render and upload service, backend just uses in-memory dictionary for job management.
Assumptions and dependencies
Deployments
- Embedding service in Hugging Face spaces: Deployed qwen3-embedding:0.6b which provides embedding for a given input.
- Code executor service in Hugging Face spaces: Hosted a service exposed by fastapi which executes the Manim code and returns the command line error on execution.
- Render service deployed in render.com: Hosted a service exposed by fastapi for triggering job in Github Actions and getting back result from Github Actions (using webhook). Abstracts away the webhook and long polling logic.
- Cron job service deployed in render.com: Hosted a fastapi service where the endpoint is triggered by the cron job and the logic for deletion of videos from Cloudinary is performed (to stay within free tier). Registered the cron job in cron-job.org
- Main backend (Langgraph workflow) deployed in render.com: Used fastapi to expose endpoints for triggering the langgraph workflow and getting back result by long polling.
- NextJS frontend deployed in vercel.com: Deployed frontend with responsive design (NextJS with Tailwind CSS) in vercel.com. Checkout enginimate.vercel.app to visit the website.
- PostgreSQL database provided by Neon DB
Design choices
Language and frameworks choices
- NextJS for frontend - SSR capabilities, optimizations and familiarity.
- Fastapi for backend - simple, highly performant and familiarity.
- Langgraph for agentic workflow - offers more customization and extensibility compared to other frameworks.
Architectural decisions
- Why planning of steps - Decomposing the user query into multiple sub-steps is essential for smaller models to handle the task effectively without requiring larger models. This has cost benefits but the price to pay is latency and requires robust architecture to handle multiple points of failure.
- Why iterative evaluation of steps - My initial attempt was to evaluate the steps in parallel and form short code snippets/videos for each step which will be compiled together by the synthesizer. Although this seems convincing enough to reduce the latency significantly, each step depends mostly on the previous steps for creating an animation and making the steps completely independent of each other was not possible. Hence, the only way is to modify the existing code iteratively for each step.
- PG Vector Store for embeddings - highly performant compared to pure vector database for smaller datasets, same postgres database used for storing metadata of rendered videos can be used for storing embeddings in a separate table.
- Hugging face spaces for embed service - easily host machine learning models for free if persistent storage is not required (16GB RAM, 2vCPUs): can easily host qwen3-embedding:0.6b and give faster speeds even without GPU.
- Long polling used for retrieval of code snippets, documentation and docstrings because SSE is not required and this can be a bit of long running task, only one way communication from server to client required. Similar argument for using long polling for communication between frontend and backend.
- Semantic evaluation of code against certain criteria were required because the coding agent was able to skip some steps without writing any code essentially avoiding syntax issues. Hence the required goal will not be achieved or there will be overlapping elements in the visuals which wasn’t appealing visually.
- Cloudinary for storing videos - free tier limits are mostly good enough and if required can be removed after a specific duration by cron job.
- Why Github Actions for rendering videos from code snippets - For rendering Manim videos, a minimum of 4GB RAM is required. My initial attempt was to use the Hugging face spaces VM deployed for executing code (the one used by the evaluator agent to check for syntax issues in the code), but then as soon as the video is rendered it gets garbage collected by the HF Space. This aggressive garbage collection gave no time for me to upload the video to Cloudinary before the video gets deleted. I can’t seem to find any other free providers which give a minimum of 4GB RAM and I do not want to use up the AWS/Google Cloud free tier just for this project. I came across Github Actions which provides 4 vCPUs, 16GB RAM, 14GB SSD. The only limitation is that it provides just 2000 minutes per month for private repositories, but still this seemed to be generous enough for my use case.
- cron-job.org for deployment of cron job: provides generous free tier compared to any other platforms. I made it call an api every 30 mins and the api (hosted in render.com) runs a sql query to fetch the urls created in the last 30 minutes and deletes them from cloudinary essentially maintaining a time window for users to download the video as well as staying within the free tier.
- render.com for deployment of backend and its services (render service, cron job, main backend for langgraph) - simple deployment of fastapi apps, good enough free tier for our deployments
- vercel.com for deployment of frontend - simple deployment of NextJS frontend
- Tailwind CSS as CSS framework - provides simplicity and extensibility, easy to create responsive web design
Models
- Llama 3 70b in reasoning agent: most performant model provided by Groq in free tier, short and crisp responses.
- Llama 3 8b in query decomposer agent: smaller model is good enough for the task - cost efficiency.
- moonshotai/kimi-k2-instruct-0905 for coding agent: highly efficient model for coding and tool calling - got better results compared to other models
- gpt-oss-safeguard-20b for evaluator agent: good enough model for detecting semantic problems in the code based on several criterias.
- qwen3-embedding:0.6b model for embedding: highly effective model for embedding code snippets along with documentation, top performer for embedding python code.
Back of the Envelope calculations
- The DAU and number of concurrent limits are governed by LLM provider Groq (most constrained part in the workflow). I tried deploying my own coding model in VPS but that gave much slower inference.
- DAU approx 10 per day and number of concurrent users is governed by tokens per minute (for coding agent: 8000 TPM). (20000 characters / 4.2 characters per token = 4761 tokens). Hence concurrently can handle 2 users at the worst case but there is retry logic which can retry in the next minute or so, thus can handle a lot more number of users especially if model fallbacks are added to the coding agent.
Dependencies
- render.com - 512mB RAM, 750 hours per user per month (service spins down after inactivity) (bearable doesn’t affect DAU much)
- vercel.com - not significant limits affecting DAU
- Hugging face spaces - 2 vCPUs, 16GB RAM, 50GB ephemeral storage(*.mp4 gets garbage collected), no GPU (can’t host large coding models) (other limitations are not so clear, but under the hood its an EC2 instance)
- Neon for PostgreSQL - 0.5GB storage, 190 hours per month (based on my calculation: 2mB for docs and 10kB for each row of metadata, so I can store atleast 50000 rows which is more than enough).
- Cloudinary - 100mB per video file, 25 monthly credits across storage, bandwidth and transformations (1 credit=1000 transformations, 1GB storage or 1GB bandwidth), 500 admin api requests per hour - (no transformations used) (bandwidth required: 7mB of static assets per user + 2mB(avg size of generated videos) per user), therefore can hold upto 2400 users per month (since storage is mostly constant - cleared up by cron job).
- Github Actions - 2000 build minutes per month(limit for private repository) - (3 minutes per user + 3 minutes of render time on avg approx 6 minutes per user = 333 users per month).
- Groq
- The most restrictive model being used in the workflow is openai/gpt-oss-safeguard-20b (30 RPM/ 1000 RPD/ 8000 TPM/ 200000 TPD): Most likely TPD (tokens per day is likely to exhaust) meaning (200000/(20000: approx tokens across all steps used by evaluator)) = 10 per day
Storage requirement calculation
- Docs: 6812 bytes per row and total of 136 rows = approx 900kB
- Rendered video storage metadata: 7321 bytes per row on an avg.
- Neon limits = 512mB free tier
- Say 510mB for video storage, meaning 510*1024*1024/7321 = 73000 rows of rendered video metadata can be stored.